使用BCC提供的转换器将P4转换为eBPF的流程分析
BPF、eBPF 和 IO Visor
BPF(BerkeleyPacketFilter,伯克利数据包过滤器)允许在内核态下丢弃那些不需要的数据包,从而避免所有包都从内核态拷贝到用户态的网络监控工具而提升性能(也可采用 LIBPCAP 函数库实现过滤与捕捉)。
Linux 3.15 开始引入 eBPF。其扩充了 BPF 的功能,丰富了指令集。到了 eBPF 后,虚拟机的功能并都更加强大,使得我们对数据包的操作都可以在内核灵活地实现,完全不需要加载重新编译,而且可以在线替换等,灵活性大大增加。数据平面也就变得更加灵活(可以随时改变对每个数据包的处理行为)。且在内核中完成该功能使得性能大大提高(避免从内核到用户态的拷贝)。
IO Visor 的基本思路是使用一种灵活的方式在内核实现对网络数据包的处理,而不需要像传统的方法那样通过加载内核模块的方式来实现、或者通过繁重的系统调用在用户态计算。从而实现一个灵活的数据平面,加速 NFV。
具体说明可以参考:
- IO Visor 仓库对于 eBpf 的介绍:https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
- IO Visor 官方网站:https://www.iovisor.org/technology/ebpf
- Linux Kernel 说明文档:https://www.kernel.org/doc/Documentation/networking/filter.txt
所以,如果可以将 P4 代码转为 eBPF 的代码,那么它将可以直接在 Linux 中以原生的方式运行。可以认为 eBPF 能够作为类似 Behavior Model 的 P4 后端。
P4 转 eBPF 编译器
转换器
仓库地址:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4
它的目的是将 P4 转换为 C 语言描述的 eBPF 代码片段,然后使用 BCC 工具来将 C 语言代码转换为 eBPF 代码,然后在 Kernel 中运行。
依赖——P4-hlir
仓库地址:https://github.com/p4lang/p4-hlir
HLIR:highlevel intermediate representation 它可以将 P4 语言编译为 P4 的前端中间语言,转换器需要依赖此中间语言。
运行环境——BCC
仓库地址:https://github.com/iovisor/bcc
使用 BCC 的库可以直接载入转换器转换后的 C 语言,并切转换为 eBPF 并运行。
编译器代码分析
文件结构(大致说明)
| Name | 作用 |
|---|---|
| compilationException.py | 异常处理 |
| ebpfAction.py | action 相关 |
| ebpfConditional.py | 状态和跳转(if)相关 |
| ebpfCounter.py | 计数器相关 |
| ebpfDeparser.py | Deparser 相关 |
| ebpfInstance.py | 对 Header、Metadata 和 HeaderStack 的声明 |
| ebpfParser.py | 和 Parser 相关 |
| ebpfProgram.py | 关键控制代码,从经过 hlir parser 以后的中取出相关元素,生成对应的类,并且还可控制代码的翻译过程 |
| ebpfScalarType.py | 将 P4 的字段长度映射到 C |
| ebpfStructType.py | 和 Header 类型和 Struct 类型相关 |
| ebpfTable.py | 和 match_field 流表相关 |
| ebpfType.py | 转换成 C 语言类型的基类 |
| p4toEbpf.py | 命令行输入/调用 HLIR 和 ebpfProgram 解析 P4 代码,并生成 C 语言结构,最后输出 |
| programSerializer.py | 生成 C 语言代码的序列化工具 |
| README.txt | 项目介绍 |
| target.py | 配置和头文件相关 |
| topoSorting.py | 拓扑排序(这里不太明白) |
| typeFactory.py | header 类型表 |
处理流程
总流程 
构建 eBPF 实例的准备流程

转换为 C 语言序列化的流程
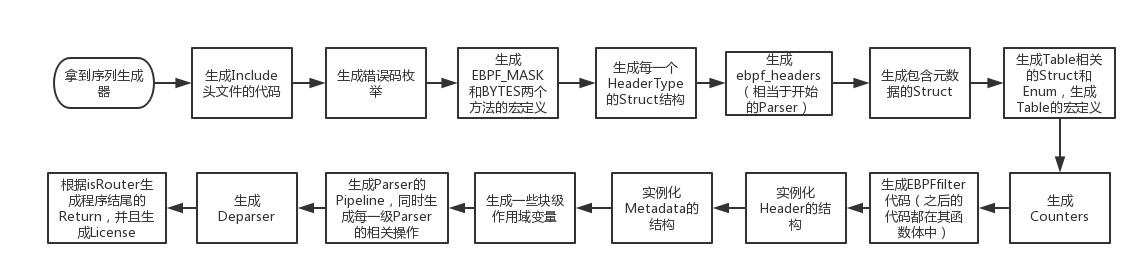 测试用例运行流程
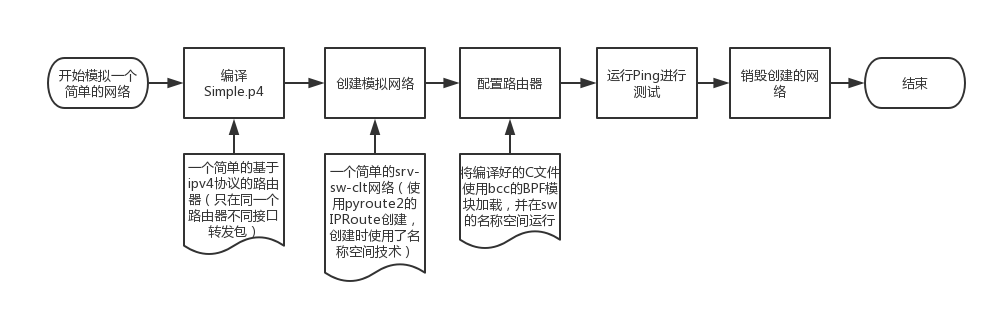
测试用例运行流程
可以使用转换器目录下的 test/endToEndTest.py 来测试示例代码
参考资料
了解 IO Visor 的技术基石 BPF 与 eBPF:http://blog.csdn.net/quqi99/article/details/49820419