使用Scrapy写个增量式图书爬虫
需求分析
爬取图书(特别是小说)数据并存储,用作之后的分析。 可以爬取的站点有 Amazon、京东、当当、腾讯旗下的一众小说网站(腾讯文学、创世中文、云起书院)、起点中文网等等。
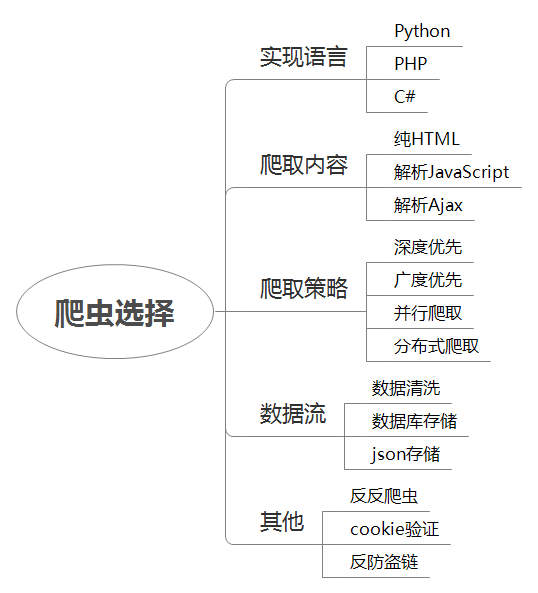
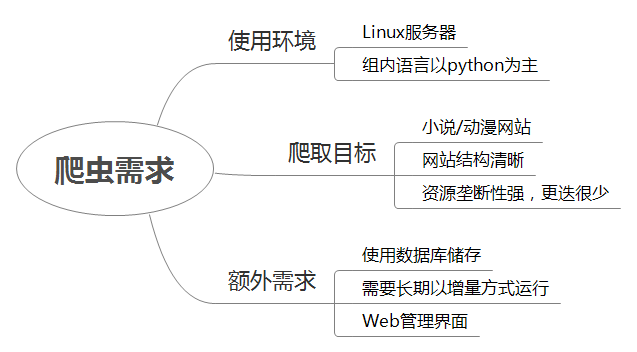
爬虫选择
根据自己熟悉的语言来调查分析网上流行的爬虫。 并最终根据自身情况选择了 Scrapy。 

以云起书院为例来分析相关网站的模式

根据分析可以看出来,网站的层级有三层:图书列表,图书内容和图书评论。在爬取的时候可以根据三层的内容分别设计 Item 和数据库并进行爬取和存储。
Scrapy 工作方式
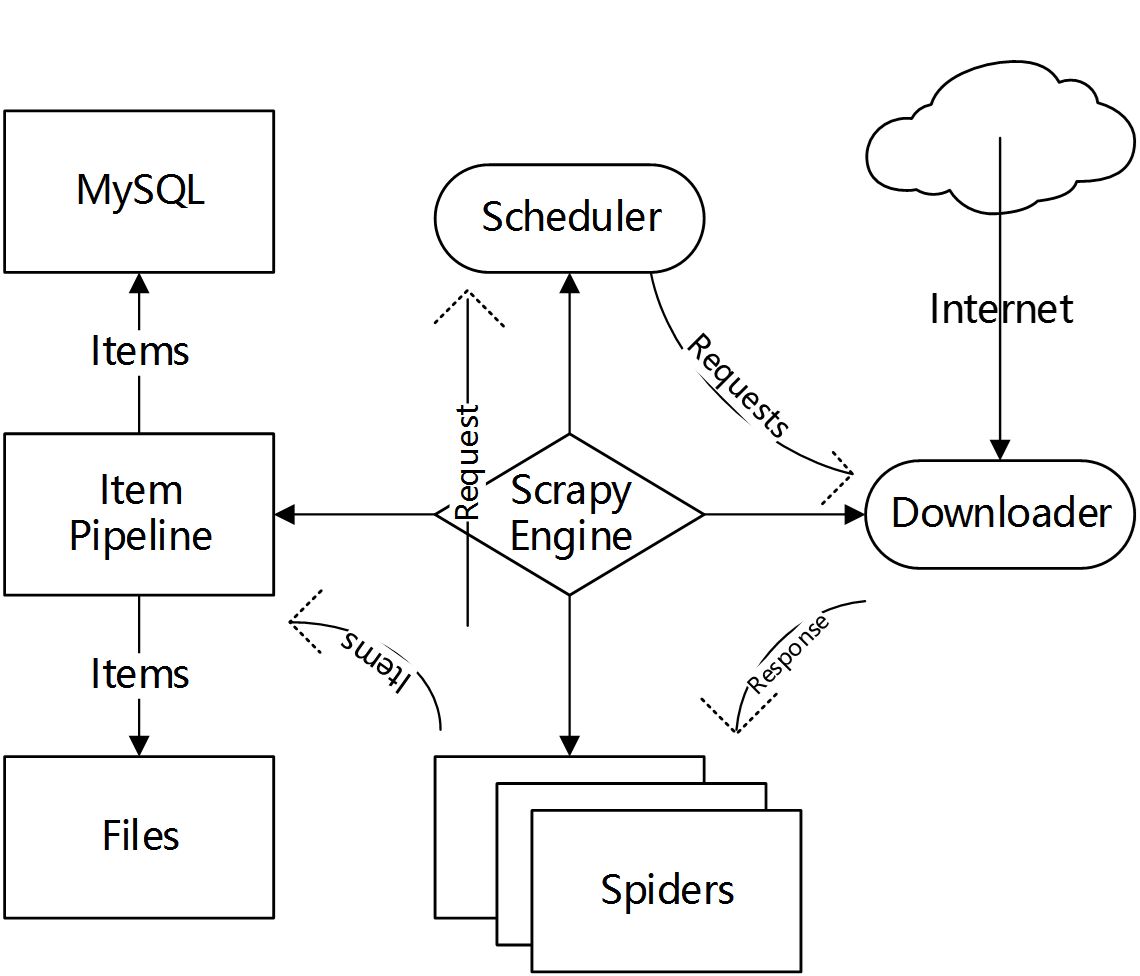
有许多地方 Scrapy 框架都自动完成了,需要做的就是定义要爬取的 URL 以及将 URL 里面的内容使用 Selector 匹配道,在 Pipeline 中做数据清洗并且将 Item 里面的内容存入数据库或者文件。
分层增量爬取架构
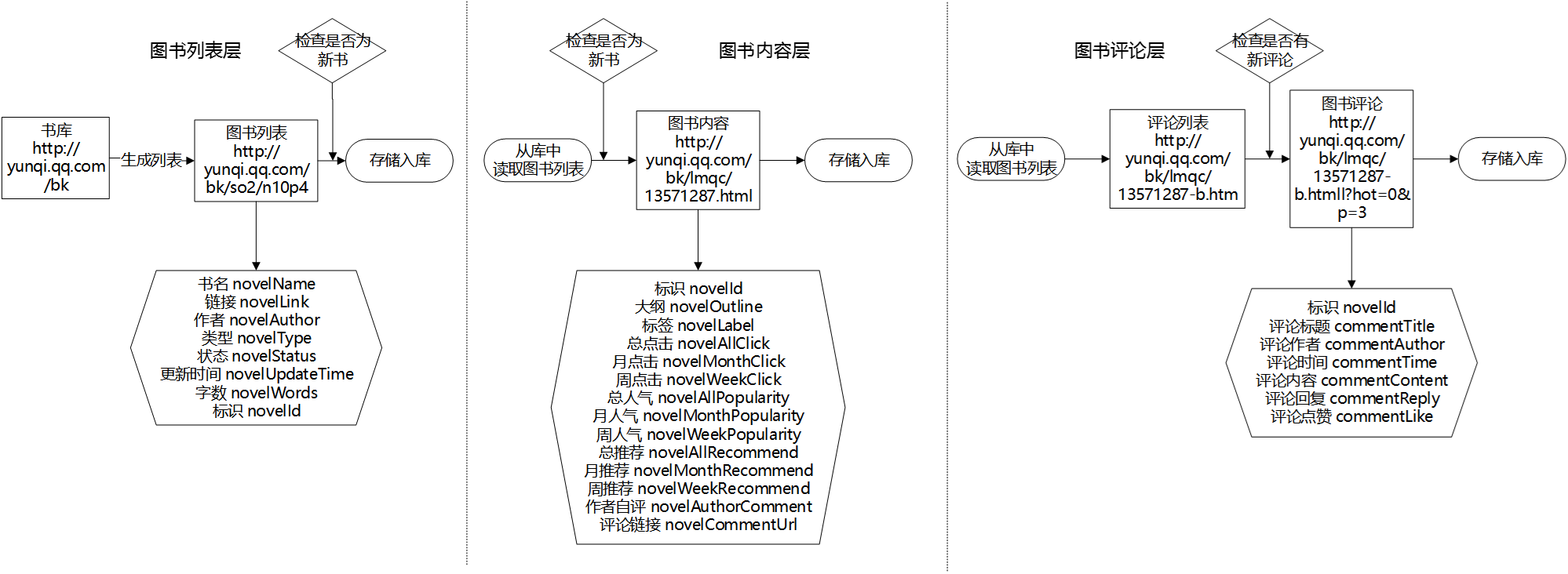
增量爬取的方法就是分别对每一层写一个 Spider,分别进行爬取,爬取之后进行存储并加入标识,之后更新的时候只更新新加入的图书而不去重新将所有的图书重新爬取。
利用 Shell 指令实现自动增量爬取
实现爬虫每天自动运行
1 | //Bash |
1 | //cronList.sh |
每次开启任务,按照广度优先进行分层爬取
1 | //run.sh |
运行效果
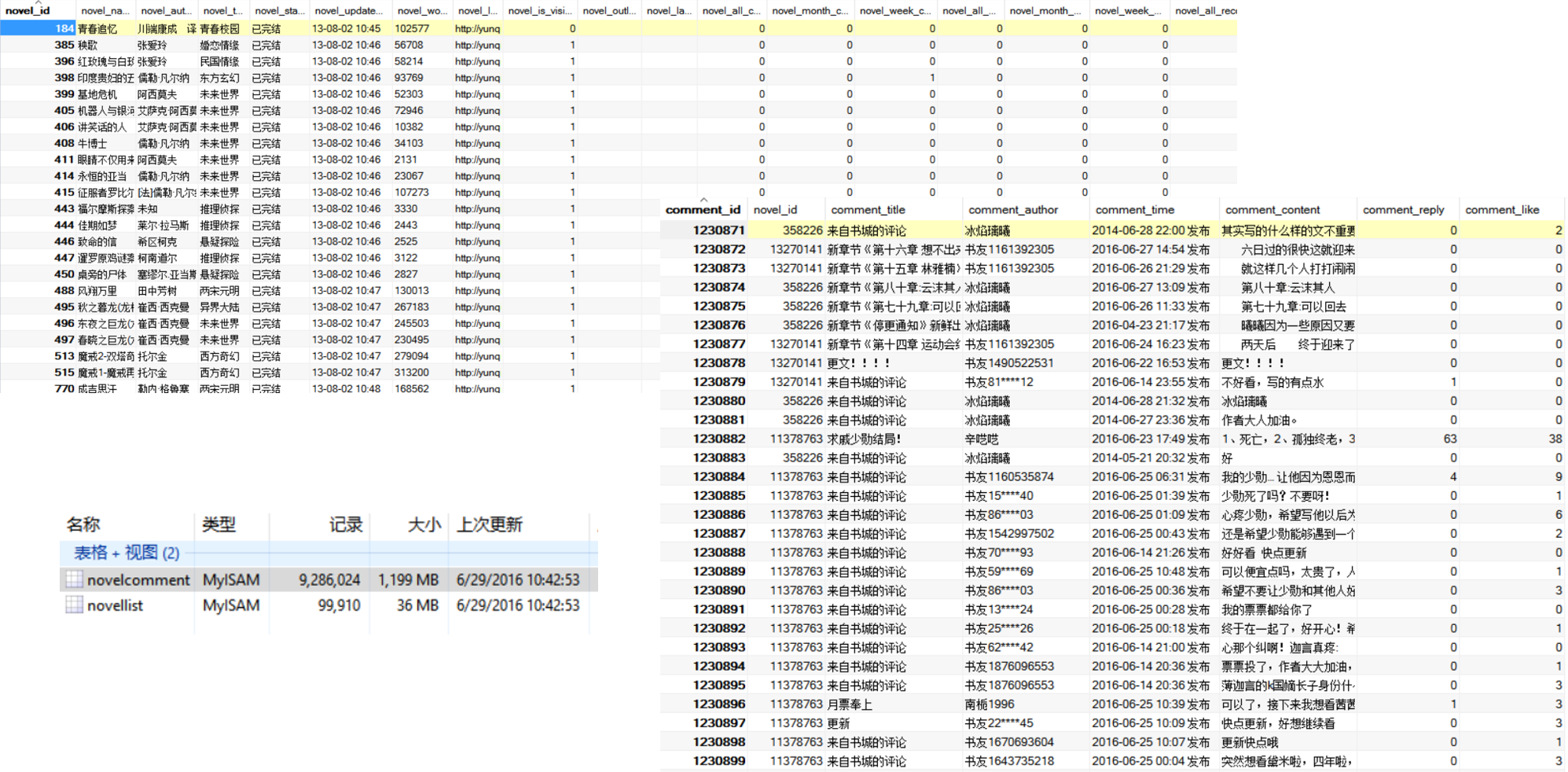
后期工作
在爬取之后还应该使用 Supervisor 或者 Scrapyd 进行托管,以更稳定的方式运行。之后有空会继续更新一套可视化爬虫工具并开源。
参考
- Scrpay 文档:http://doc.scrapy.org/en/1.1/index.html
- Scrapyd 文档:https://scrapyd.readthedocs.io/en/latest/index.html
- Scrpay 使用笔记:http://www.q2zy.com/articles/2015/12/15/note-of-scrapy/
- Scrapy 使用以及 Xpath 的一些坑:http://www.tuicool.com/articles/EVfqI3
- amazon 图书爬虫(非增量式,已开源):https://github.com/imaginezz/amazonBookSpider
相关文章